
Los errores de indexación son uno de los peores problemas con los que se puede encontrar un webmaster. Algunos solo afectan a la rastreabilidad e indexabilidad de tu sitio web, lo cual ya es malo de por sí. Pero otros, como los bucles de redireccionamiento, son problemas que pueden bloquear el acceso a cualquiera, usuario o robot.
Existen multitud de factores que influyen en cómo los buscadores rastrean e indexan tu sitio web. La enorme y compleja casuística de los errores de indexación daría, más que para un post, para un libro entero.
Por eso, en este artículo he querido recopilar los errores de indexación más frecuentes que afectan a un sitio web, cuál la causa más probable y cómo arreglarlos. Sé que me dejo algunos en el tintero. Más adelante los iré incluyendo, o puede que haga un post dedicado para los más complicados.
Pero ahora, vamos allá…
Contenidos de la página
¿Qué son los errores de indexación?
Un error de indexación básicamente es un problema que afecta a la capacidad de los buscadores para rastrear e incluir una o varias páginas de tu sitio web en el índice de búsqueda. Esto significa que las URLs con errores de indexación no aparecerán en los resultados de búsqueda. Mala cosa, ¿verdad?
Es esencial para la salud de tu sitio web y de tu posicionamiento orgánico controlar y solucionar los errores de indexación cuanto antes. Para ello, contamos con un sinfín de herramientas que nos permiten analizar nuestra web en busca de tales errores.
Aquí me voy a centrar en Search Console de Google porque es gratuita y además, porque la forma en que nos presenta la información es muy intuitiva. Los errores de indexación en Search Console aparecen el informe de cobertura.
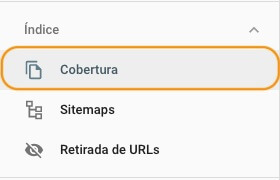
Este apartado de la herramienta para webmasters de Google es muy completa y proporciona información acerca del estado de indexación de nuestro sitio web. Además de los errores, puedes ver las páginas indexadas y las excluidas por otras razones, así como subir y modificar tus sitemaps.
Pero en el post que nos ocupa nos centraremos en los errores de indexación (los que aparecen en rojo). Si hacemos scroll hacia abajo, veremos los distintos tipos de errores que Google ha encontrado en nuestra web, así como las URLs afectadas y el estado de validación (más adelante te explico qué es).
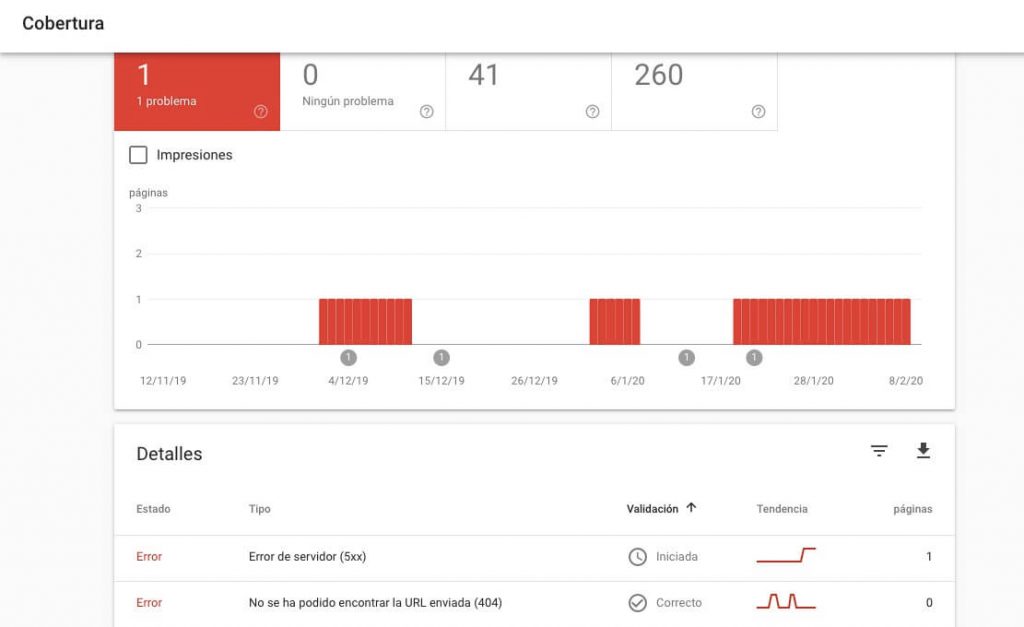
Haciendo clic en un tipo de error concreto se nos abrirá una ventana con más detalles, las URLs afectadas y la fecha en que se detectó el error por primera vez. También desde aquí podemos analizar la página con la herramienta de inspección de URLs e iniciar el proceso de validación una vez solucionemos el problema. Pero de eso nos encargaremos más adelante.
Los errores de indexación más comunes
Como decía al principio, hay muchos tipos de errores de indexación y cada uno de ellos puede deberse a varias causas. Si entrara en tanto detalle este post sería demasiado largo, así que he hecho una recopilación de los que considero más importantes, centrándome en la causa o casusas más probables. Aún así pretendo ir actualizando este artículo con otros errores típicos que se me ocurran.
No subir un sitemap de tu web
Aunque no es un error de indexación como tal, no tener un sitemap actualizado en tu web es dejar la puerta abierta a posibles problemas en el futuro. ¿Por qué?
Pues porque con un mapa todo es más fácil. Si tienes que buscar los sitios de interés en una ciudad que no conoces, ¿a que un mapa te viene de perlas? A Google le pasa lo mismo. Un sitemap le dice las páginas que quieres indexar sin tener que esperar a que el buscador las encuentre por sí mismo.
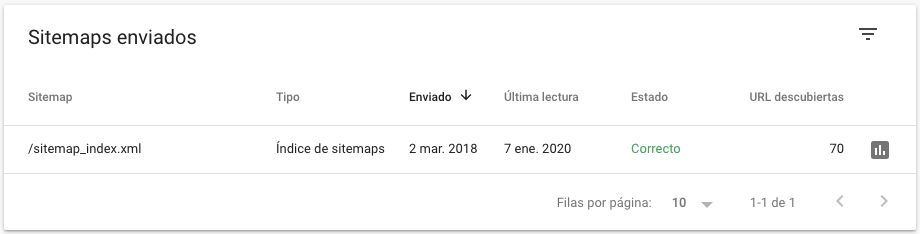
Además, al indicarle qué páginas son las que quieres que indexe, si detecta algún problema (como un bloqueo o un 404), te avisará del error para que puedas corregirlo a tiempo. Dos ventajas en una.
Bloquear una URL sin querer
Este error de indexación es más frecuente de lo que crees. Y muchas veces es por puro despiste. A veces no eres ni siquiera consciente de que estás bloqueando .
Puede pasar que sin darte cuenta estés bloqueando una URL en tu robots.txt porque está dentro de un directorio restringido con una directiva disallow. Por ejemplo, imagina que tienes la siguiente instrucción en tu archivo de robots:
Disallow: /categoria/
Si la estructura de tus páginas es /categoria/nombre-de-la-pagina, le estás indicando a los buscadores que no rastreen la categoría en cuestión, pero también las páginas que se encuentran en esa categoría, lo cual sería un error.
Si no quieres cambiar la estructura de tus enlaces, porque es un rollo andar redirigiendo todo, puedes quitar la barra al final de la línea para indicar que quieres bloquear solo la URL de la categoría y no todo el directorio.
Olvidarte de quitar un disallow
Es otro de los errores de indexación que puedes cometer si no te das cuenta. Puede ser que en algún momento no quisieras que Google rastreara alguna página que estabas editando y la bloqueaste en el robots.txt.
Pero ahora que ya la tienes lista, quieres que aparezca en los resultados de búsqueda. Y para que los robots puedan rastrearla, has quitado la etiqueta noindex pero te has olvidado del disallow que está impidiendo el paso a los bots de rastreo.
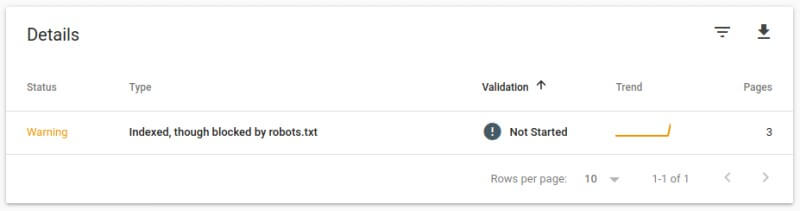
Si la has incluido en tu sitemap, Google se hará un lío y te mostrará un error de indexación en Search Console. Pero si no, el problema pasará completamente desapercibido en el informe de cobertura como una página excluida más. Es bueno echar un vistazo de vez en cuando para comprobarlo.
Usar la directiva noindex en tu robots.txt
En septiembre de 2019 Google dejó de dar soporte a la directiva noindex en los archivos robots.txt. Esto no quiere decir que otras directivas dejen de ser efectivas. Simplemente se trata de un paso para estandarizar el uso del protocolo de exclusión de robots.
En su lugar, deberías insertar las meta etiquetas noindex en el <head> de cada página para indicar que no quieres que se indexe, o usar la directiva disallow en el archivo de robots para bloquear las URLs que no quieras indexar.
Y si Google indexa alguna página por error, recuerda que siempre puedes eliminarla manualmente del índice con la nueva herramienta de retirada de URLs de Search Console.
Crear un Soft 404
Un Soft 404 es una página que devuelve un código http 200 en lugar de un 404 para indicar que la URL no existe. Se suele utilizar para engañar a los buscadores y así evitar los tan temidos errores 404.
Puede que esto te parezca una buena idea, pero en verdad te estás haciendo un flaco favor. Dada la cantidad de webs que hay en Internet, los buscadores tienen que optimizar el tiempo que tardan en rastrearlas. El tiempo que dedican a cada web se conoce como crawl budget.
Si al acceder a una página los robots obtienen un código 404, indicando que esa URL no existe, no perderán más tiempo en rastrearla. Pero si obtienen un 200, creerán que hay una página válida e intentarán acceder a ella cada vez para ver si ha cambiado.
Para evitar que Google pierda tiempo rastreando una página que apenas tiene contenido, es mejor usar una página 404 personalizada. A los usuarios les puedes mostrar una web amigable al tiempo que informas de que esa página no existe.
Bucle de redireccionamiento
Uno de los peores problemas con la indexación son los bucles de redireccionamientos. A veces puede pasar que, al intentar acceder a una página, el servidor te redirija a otra, y luego a otra, y así hasta el infinito. Tras sobrepasar un número de intentos, los navegadores te mostrarán un mensaje del tipo “Demasiados redireccionamientos”.
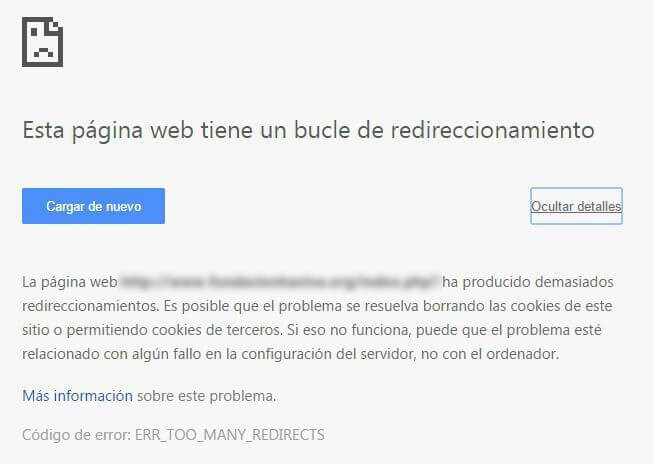
Obviamente esto no es bueno, porque los robots que se pasen por allí y entren en un bucle al final se irán sin rastrear tu página, y es posible que eso te penalice. Tampoco a los usuarios les molará nada encontrarse con un mensaje de error.
Los bucles de redireccionamiento tienen arreglo, aunque a veces es un verdadero quebradero de cabeza dar con la solución, ya que pueden deberse a muchas cosas. Antes de nada, te recomendaría vaciar todas las cachés (tanto la de tu navegador como la del servidor) y desactivar cualquier plugin o herramienta de caché que estés usando. A veces es tan sencillo como eso.
Otra de las causas más probables es que algún plugin de WordPress esté causando el bucle. Lo mejor es desactivarlos todos e ir probando uno a uno hasta que salte la liebre. Entonces habrás dado con el culpable. Si tras cambiar la configuración, el error vuelve cuando actives el plugin, lo mejor es que lo elimines por completo. Los plugins obsoletos pueden ser un foco importante de problemas.
Si al desactivar todos los plugins, el problema persiste, comprueba tu archivo .htaccess. Este es el encargado de gestionar todas las redirecciones en tu sitio web. Pero antes de tocar nada, haz una copia del archivo por si acaso. Editar este archivo sin cuidado puede bloquear por completo el acceso a tu web.
No te preocupes si no entiendes cómo funciona. Si utilizas WordPress, accede a tu servidor y borra por completo este archivo (después de haberte descargado una copia, claro). Ves a los ajustes y guarda la configuración de los enlaces permanentes sin cambiar nada. Esto simplemente creará un nuevo .htaccess con una configuración limpia de errores.
Resumiendo
En este post hemos repasado algunos de los errores de indexación más frecuentes. En mi opinión, estos son los más importantes. Pero si crees que me he dejado algún error de indexación que deba estar en esta lista, puedes dejarme un comentario. Te lo agradeceré enormemente. 🙂
{kind=link}